La inteligencia artificial (IA) ha dejado de ser una funcionalidad aislada para convertirse en un ecosistema que lo abarca todo. En la actualidad, está presente en todas las fases del análisis de datos ya que se apoya en disciplinas de machine learning (ML) y Deep learning. Esto le permite realizar tareas de forma rápida y con alto nivel de especialización.
La IA es una herramienta excelente en cuanto a análisis de datos se refiere, por lo que cada vez más empresas y profesionales cuentan con ella para la realización de determinadas tareas. Es decir, con ella es posible limpiar datos o realizar predicciones.
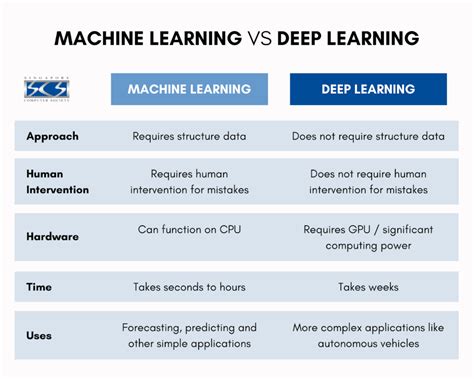
El Machine Learning como Pilar Fundamental
El machine learning es el pilar fundamental de la mayoría de las herramientas de IA para el análisis de datos ya que se encarga de enseñar a los algoritmos cómo deben aprender los patrones partiendo de datos, esto hace que puedan tomar decisiones de manera autónoma sin intervención humana. Por su parte, el Deep Learning es aquel que utiliza redes neuronales para realizar este aprendizaje, lo que lo hace imprescindible en modelos más complejos.
El ML, con su capacidad para manejar grandes conjuntos de datos y descubrir patrones complejos, representó un avance significativo. Los algoritmos de ML, como los árboles de decisión y las redes neuronales, permitieron un análisis más profundo y la creación de modelos predictivos más precisos. Esta evolución expandió notablemente el horizonte de lo que podíamos lograr con el análisis de datos.
IA vs. Análisis de Datos Tradicional
Llegados a este punto, es importante señalar cuáles son las principales diferencias entre el modelo tradicional de análisis de datos y el potenciado por IA. Mientras que el primero se basa en reglas predefinidas, fórmulas y modelos manuales para llevar a cabo los análisis, el potenciado por IA es capaz de funcionar de manera autónoma. Es decir, la IA aprende sola, mejora con el tiempo y se adapta al contexto sin necesidad de que tenga que reprogramarse de manera constante.

Aplicaciones de la IA en el Ciclo de Vida del Análisis de Datos
Es necesario destacar que la IA puede aplicarse en todas las tareas del ciclo de vida del análisis de datos. Es decir, en la recopilación, la limpieza de la información, la visualización y la predicción.
- Herramientas de IA para la detección de anomalías y la imputación de datos: la IA es capaz de detectar inconsistencias y corregirlas de manera automáticas basándose en los patrones aprendidos, ya que uno de los primeros retos a la hora de analizar es trabajar con datos erróneos o incompletos.
- Análisis exploratorio (EDA) y visualización de datos: los modelos de IA cuentan con herramientas como Tableau o Power BI integradas que hacen que se puedan entender las relaciones entre las variables de manera visual.
Herramientas Imprescindibles para el Análisis de Datos con IA
Entender cómo la IA puede ayudarte en el análisis de datos, pasa por conocer qué herramientas son las imprescindibles dentro de este ámbito.
- Python: El análisis de datos “habla” en Python, un lenguaje que cuenta con una sintaxis sencilla y una gran comunidad de respaldo que deberás dominar si quieres adentrarte en este mundo.
- R: R, por su parte, es un lenguaje con un enfoque estadístico, por lo que será una herramienta que deberás dominar si tu campo de especialización es la investigación científica.
- AutoML (Automated Machine Learning): AutoML (Automated Machine Learning) es capaz de crear modelos sin necesidad de programar. Es decir, las plataformas de este tipo automatizan el preprocesamiento, la selección de algoritmos, entrenamiento y validación.
Si quieres aprovechar al máximo el potencial que te ofrece la IA en cuanto a análisis de datos se refiere, es imprescindible dominar los tres pilares que lo conforman.
Modelos Estadísticos Fundamentales en la IA
Inteligencia artificial (.AI) es la ciencia y la ingeniería de crear máquinas y sistemas inteligentes que puedan aprender de los datos, realizar tareas y tomar decisiones. Para lograrlo, la IA se basa en varios modelos estadísticos que capturan los patrones, las relaciones y las incertidumbres de los datos y el entorno.
Probability theory is foundational to machine learning design. An understanding of stochastic processes and the calculus to work with them is also helpful to develop machines with varying learning "paths". Probability theory is a cornerstone of AI, allowing us to tackle uncertainty in various applications. It underpins Bayesian inference for updating beliefs with new data, drives machine learning models like Naive Bayes and Hidden Markov Models, and aids in reinforcement learning. In NLP and computer vision, it models language sequences and spatial relationships in images. Probability theory also plays a vital role in anomaly detection, Monte Carlo methods, robotics (e.g., SLAM), and game theory.
Statistical models are pivotal in AI, allowing us to glean insights from data. They establish a mathematical foundation for comprehending patterns, predicting outcomes, and informed decision-making.
Statistical AI models include linear regression (for trend prediction), logistic regression (binary classification), decision trees (hierarchical decision-making), SVMs (high-dimensional classification), naive Bayes (text classification), KNN (similarity learning), and neural networks (complex tasks like image/speech recognition). Statistical models are fundamental in AI. Examples include Linear Regression for continuous predictions, Logistic Regression for binary classification, Decision Trees for data partitioning, Random Forest for ensemble learning, SVM for binary classification, Naive Bayes for text analysis, and Neural Networks for diverse applications like image recognition. K-Means Clustering groups data based on similarity. The key is choosing the right model for your problem and data, rather than blindly applying complex models. Simpler interpretable models often outperform black-box models. Ensembling multiple models can improve robustness.
Modelos de Regresión
Regression models, a key component of supervised learning, uncover the connection between a dependent variable and one or more independent variables. They serve multiple purposes, including prediction, estimation, and explanation. For instance, these models enable forecasting house prices from their features, gauging the impact of treatments on patient outcomes, or elucidating the factors affecting product demand.
The regression models aim to find the best-fitting line/surface to map inputs to outputs. The technical challenges are selecting the right regression method, feature engineering, model training, and evaluation metrics. LR, Ridge, Lasso, and polynomial regression are generic methods. Complex models like SVM or NNs delve into complicated patterns. Next, the model training is guided by methods such as gradient descent and kernel methods.
The choice between linear and nonlinear regression depends on the nature of the variable relationships. With regression models, check residuals for normality, homoscedasticity, autocorrelation. Use cross-validation to avoid overfitting. Try transformations or regularizations to improve linearity. Select parsimonious models to avoid overfitting. Evaluate predictive accuracy on holdout sets.
Modelos de Clasificación
Classification models are commonly used supervised learning techniques, addressing the challenge of categorizing data into distinct classes. Key technical considerations include selecting the right classification method, optimizing features through engineering, rigorous model training, dealing with imbalanced data, regularization techniques, cross-validation for validation, hyperparameter tuning, and choosing appropriate evaluation metrics like accuracy, precision, recall, F1-score, and AUC-ROC.
Classification models, a vital component of supervised learning, are designed to assign labels or categories to inputs based on their features. These models find extensive use in object identification, recognition, and situational diagnosis. They facilitate tasks such as identifying a flower's species from its petals, recognizing a person's face from their image, or diagnosing diseases based on symptoms. The classification models can be categorized as binary or multiclass, depending on the number of possible labels or categories.
Imagine sorting laundry - your brain uses color, fabric, and size to categorize socks vs. shirts. Classification models do the same with data, but digitally!
For classification, handle class imbalance with sampling or cost-sensitive learning. Use cross-validation for model selection and hyperparameter tuning. Evaluate models with metrics like precision, recall, ROC curve, not just accuracy. Analyze misclassified cases to gain insights.
Algoritmos de Clustering
Clustering algorithms act as data detectives, uncovering hidden patterns and grouping similar items together. They're like librarians for your data, sorting books (data points) into meaningful sections (clusters) based on shared characteristics. With clustering, determine the optimal number of clusters using elbow plots or information criteria. Standardize data and choose distance metrics suited for data type. Generate cluster profiles to interpret and label clusters. Assess clustering quality with silhouette scores and cluster separation.
Start by clearly define the problem statement, data prep, next step would be choosing most appropriate clustering algorithm your problem and data type. Train the model by specifying the number of clusters and parameters, evaluate the of the model using metrics such as silhouette score or other index mechanism available.
Modelos Gráficos
Graphical models are a way of representing probabilistic relationships between variables. They are a probabilistic network that uses a graph to represent the dependencies between variables. Markov networks and Hidden Markov models are two examples of graphical models. Markov networks are undirected graphical models representing the probability distribution over a set of variables. They are widely used in various AI applications, including image segmentation, NLP, and speech recognition. Hidden Markov models are used to represent evolving systems.
For graphical models, learn structure from data or encode domain knowledge. Perform inference with exact or approximate algorithms like variable elimination and loopy belief propagation. Learn parameters from complete or incomplete data using EM or gradient descent.
Deep Learning
Deep learning has revolutionized many areas of AI, such as computer vision, natural language processing (NLP), and autonomous driving, by providing a framework that can learn complex patterns from large amounts of data. Convolutional Neural Networks (CNNs) are utilized for processing visual data in image recognition, while Recurrent Neural Networks (RNNs) or Long Short-Term Memory (LSTM) models manage sequential data such as audio in speech recognition. For NLP, RNNs and Transformer models are employed in tasks like translation, text summarization, and sentiment analysis.
With deep learning, use validation sets for hyperparameter tuning and early stopping to prevent overfitting. Initialize weights carefully and normalize inputs. Employ techniques like dropout and batch normalization. Transfer learn from pre-trained models when possible.
Generalized Linear Models (GLM)
In addition to the typical ML models, there are models like Generalized Linear Models (GLM) that have a more statistical foundation and, depending on the link functions and data distributions, allow for classification or regression modeling.
Introducción investigación modelos estadisticos de IA
IA Predictiva: Anticipando el Futuro con Datos
La inteligencia artificial (IA) predictiva implica el uso de análisis estadísticos y machine learning (ML) para identificar patrones, anticipar comportamientos y prever próximos eventos. Los analistas llevan mucho tiempo utilizando el análisis predictivo en las organizaciones para tomar decisiones basadas en datos. Sin embargo, la tecnología de IA predictiva acelera el análisis estadístico de datos y puede hacerlo más preciso gracias al enorme volumen de datos que los algoritmos de machine learning tienen a su disposición.
La IA predictiva llega a sus conclusiones analizando miles de factores y potencialmente muchas décadas de datos.
La IA predictiva se utiliza ampliamente para obtener información sobre el comportamiento de los clientes y optimizar la toma de decisiones en todos los sectores.
En el panorama empresarial actual, el análisis predictivo se ha convertido en un pilar fundamental para las organizaciones que buscan no solo entender el pasado y el presente, sino también anticipar el futuro. El análisis predictivo es la aplicación de técnicas estadísticas y de aprendizaje automático sobre datos históricos para prever eventos futuros o comportamientos. Utiliza modelos matemáticos y algoritmos avanzados para identificar patrones ocultos en los datos y hacer predicciones con base en estos patrones.

El Proceso de Creación de una Aplicación de IA Predictiva
La creación de una aplicación de IA predictiva requiere que una empresa recopile datos relevantes de diversas fuentes y los limpie definiendo los valores que faltan, los valores atípicos o las variables irrelevantes. A continuación, los datos se dividen en conjuntos de entrenamiento y de prueba: el conjunto de entrenamiento se utiliza para entrenar el modelo y el conjunto de prueba para evaluar su rendimiento.
Una vez que los datos están listos, los científicos de datos pueden entrenar el modelo de IA predictiva. Pueden utilizarse varios algoritmos de machine learning, como la regresión lineal, los árboles de decisión y las redes neuronales. Independientemente del algoritmo que utilice una organización, durante el entrenamiento, el modelo aprende relaciones y patrones en los datos y ajusta sus parámetros internos. Intenta minimizar la diferencia entre los resultados previstos y los valores reales del conjunto de entrenamiento. Los modelos entrenados con datos más diversos y representativos tienden a obtener mejores resultados en sus predicciones. Además, la elección del algoritmo y los parámetros establecidos durante el entrenamiento pueden influir en la precisión del modelo.
- La precisión y el rendimiento de los modelos de IA predictiva dependen en gran medida de la calidad y la cantidad de los datos de entrenamiento.
- También es esencial que las organizaciones aborden las consideraciones éticas y mitiguen los sesgos en los modelos predictivos de IA. Los sesgos en los datos o algoritmos pueden conducir a resultados injustos o discriminatorios.
IA Predictiva vs. IA Generativa
Tanto la IA predictiva como la IA generativa utilizan el machine learning combinado con el acceso a big data. La IA predictiva utiliza el machine learning para extrapolar el futuro. Las herramientas de IA generativa, como ChatGPT o Llama 3, utilizan modelos de lenguaje de gran tamaño (LLM) para generar nuevos contenidos a partir de instrucciones en lenguaje natural.
El uso de modelos de IA predictiva o IA generativa no es estrictamente binario. En lugar de elegir entre una u otra, muchas empresas pueden beneficiarse de la adopción estratégica conjunta de la IA generativa y predictiva.
Integración de la IA Predictiva en los Procesos Empresariales
Para que la IA predictiva aporte el máximo valor, debe integrarse en los procesos y flujos de trabajo empresariales existentes. Esta integración ayuda a garantizar que las percepciones y predicciones generadas por los sistemas de IA sean procesables y puedan aportar valor. La IA predictiva puede ayudar a identificar cuándo la demanda de los consumidores es mayor y una tienda debería tener más artículos en stock.
Herramientas de Análisis Predictivo con IA
- Hubspot: no solo ofrece opciones avanzadas de CRM, sino que también cuenta con un software de lead scoring impulsado por IA. Esta herramienta de análisis de datos con IA centraliza la información de clientes y prospectos, permitiendo a las empresas identificar automáticamente los leads más prometedores.
- ManageEngine Analytics Plus: Con un enfoque en la detección proactiva de problemas y la optimización de recursos, ManageEngine Analytics Plus utiliza IA para analizar grandes volúmenes de datos y prever posibles problemas antes de que ocurran.
- IBM SPSS: Como una herramienta de análisis predictivo, IBM SPSS combina análisis estadísticos tradicionales con técnicas avanzadas de aprendizaje automático.
- Futrli: Especializado en pronósticos precisos para diversos aspectos empresariales, Futrli ayuda a las organizaciones a prepararse para diferentes escenarios mediante pronósticos repetitivos, de estilo libre y de unidades.
- SAP: SAP se destaca en el uso de la inteligencia artificial en el análisis de datos para la generación de informes detallados y la analítica conversacional.
- Minitab: Reconocido por su versatilidad y su capacidad para utilizar algoritmos avanzados de aprendizaje automático, Minitab es una opción popular tanto para expertos en analítica como para principiantes.
- RapidMiner: Con un enfoque en la transparencia y la colaboración entre equipos, RapidMiner permite a los científicos de datos experimentar con flujos de trabajo de datos complejos.
- Qlik Sense: Qlik Sense se distingue por su capacidad para capacitar a los usuarios de todos los niveles dentro de una organización para tomar decisiones informadas basadas en datos.
- Alteryx: Alteryx se distingue por su compatibilidad con múltiples fuentes de datos y su capacidad para agilizar los flujos de trabajo analíticos.
- TIBCO: TIBCO ofrece soluciones avanzadas de analítica predictiva a través de herramientas como TIBCO Streaming y TIBCO Spotfire.
La inteligencia artificial ha transformado el análisis predictivo, ofreciendo a las empresas herramientas para entender mejor sus datos, anticipar tendencias y tomar decisiones estratégicas fundamentadas.
La Importancia de la Supervisión Humana en la IA
La IA es una herramienta muy poderosa que nos puede ayudar en muchas áreas, pero no deja de ser eso, una herramienta. Siempre debería tener cierta supervisión humana, especialmente en decisiones importantes. Del mismo modo, no le confiarías una decisión importante a una única persona, sin supervisión por parte de otro grupo de personas.
Transparencia y Justicia en la IA
Lo primero para que una Inteligencia Artificial sea transparente y justa es que el código sea abierto y el modelo que hay detrás sea explicable. Cualquier IA que sea una caja negra nunca podrá ser justa, porque no podremos entender qué hay detrás. Además, no solo el modelo es importante, sino los datos con los que lo entrenas. Si los datos están sesgados (y vivimos en una sociedad sesgada, por lo que la probabilidad de que tengamos datos sesgados es casi 1), el resultado de una IA entrenada con esos datos va a heredar esos sesgos.
Por ejemplo, un algoritmo de contratación que se entrena con datos históricos de empresas donde los hombres han sido contratados más que las mujeres probablemente va a perpetuar esa desigualdad y discriminar a las mujeres en el futuro, aunque la empresa diga que «la IA es imparcial».

tags: #encia #artificial #para #modelos